Implementing React From Scratch
Rob Pruzan 8/23/24
Full Code: https://github.com/RobPruzan/react-scratch
Table of Contents
- Rendering something to the screen
- useState
- Re-rendering a component
- Reconciling view nodes between render
- Conditional elements
- Efficient DOM updates
- More hooks
- Final result
- Conclusion
My goal here is to walk through my process of building react from the groundup, hopefully giving you an intuition to why things behave the way they do in react. There are many cases where react leaks its abstraction in the interface, so learning how the internals could by implemented is extremely useful to understand the motivation behind those interface designs.
But, I'm not trying to follow the same implementation that the react team did. I didn't even know the internal architecture before coding this up. Just high level concepts like virtual dom's and reconciliation.
This is also not supposed to be an optimal implementation. There are several very impressive optimizations react implements that I will not be attempting- like concurrent/cancellable rendering.
What I want to get done here is:
- Core render model (components in the component tree should re-render the same amount of times between implementations)
- Output should look the same given the same input
- Core hooks are implemented (useState, useRef, useEffect, useContext,useMemo, useCallback)
- Precise Dom updates
Rendering something to the screen
Let's start with the first goal, rendering something to the screen, using react's api. React is traditionally written through jsx, an html like syntax for instantiating components. But, the actual library has no idea of this representation. All jsx syntax gets transformed to function calls.
For example, the following snippet:
Will get transformed into:
I won't go over how this transformation happens, since this article is not about parsers :).
To get started, let's create our first example that we will create a minimal implementation for:
The first immediately obvious thing is that we have a tree-like/recursive structure to construct our view hierarchy- createElement accepts rest parameters, where the parameters are the return type of create element
So, let's go ahead and model this view hierarchy and the input type of createElement.
And then we can trivially convert the input of createElement into our internal representation:
Now that we have a representation of the view hierarchy, we can successfully apply it to the dom with the following code:
Currently, applyComponentsToDom only traverses tag elements. This is because the tree of tag elements is eagerly evaluated, as they are just strings passed to createElement, so there is no effort needed to generate the tree that we traverse. It's already built for us.
But, if we want to start rendering functional components, and composing different functional components together, we will no longer have an eagerly evaluated tree. It will look something more like:
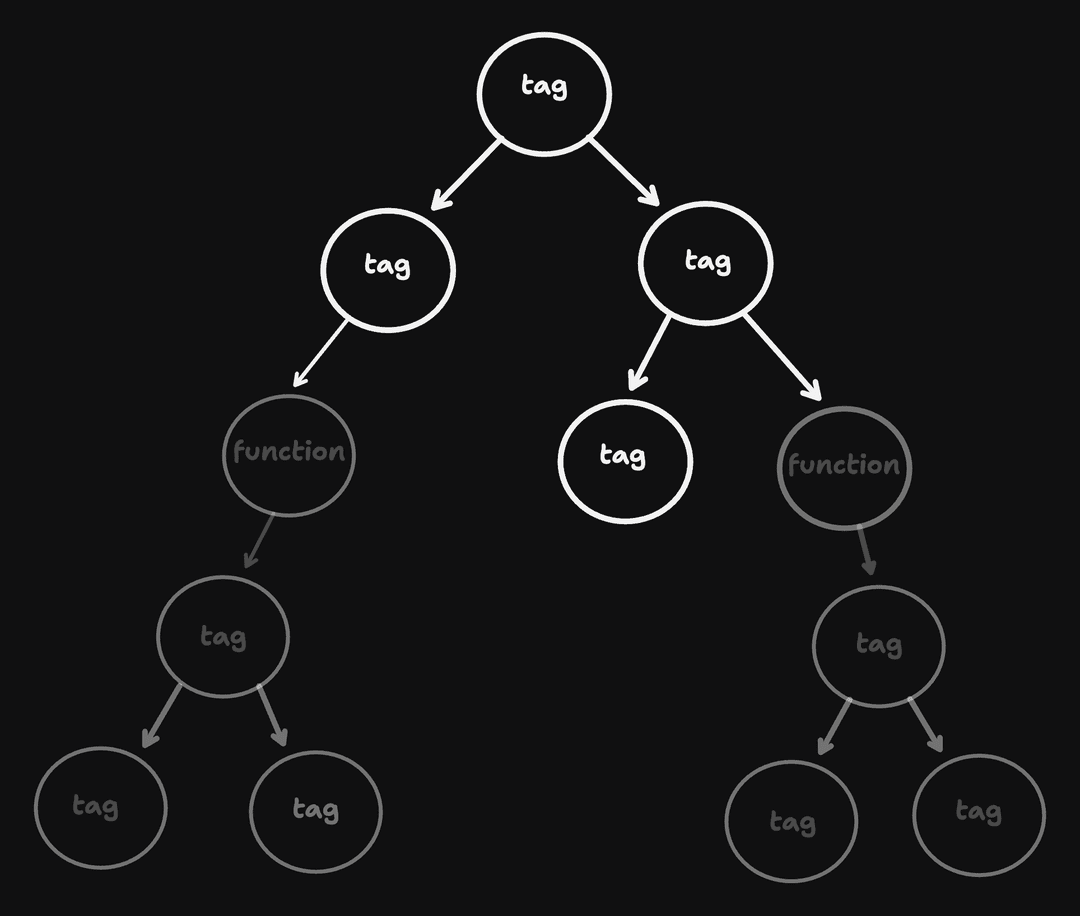
Where every function needs to be manually executed to evaluate the rest of the tree.
Another way of saying that is the "children" property in the component's metadata no longer represents a valid tree-like structure we can traverse trivially. We will have to use the HTML tag information, along with the function associated with the component, to generate a full tree we can traverse.
To do this, let's model what a node on this tree we need to build will look like
With this kind of tree, we will explicitly have fully executed nodes held inside the "childNodes" property
Our next challenge will be to actually generate this view tree given the root components metadata. The root component would be the one passed to
In this tree we are trying to make, the parent-child hierarchy is determined by the "children" property on the component's metadata.
To make a function that can turn the lazy internal metadata into a full view tree, we will need to do the following:
- create a new node for every internal metadata (which will be returned at the end of the function)
- if the metadata represents a function, run the function, recursively traverse its output, and append the recursive call's result to the child nodes of the new node
- This gives us the fully exectuted tree under the function (at most as 1 child)
- If the metadata represents a tag, get the view node for all the children's metadata by calling generateViewTree recursively. Set that output as the child nodes of the new node made for the tag metadata
- This gives us the fully executed tree under the tag node (may have many children)
What that looks like in code is:
And then we need to update our applyComponentsToDom function so it traverses this new tree
This gets us far enough to apply the view tree we generated to the dom, allowing us to compose functional components together. Our next goal will be to add some interactivity to these components
useState
Binding state to a component in react is used using the useState hook.
The first time useState is called in a component, it will bind state to the component it was called in, and associate the created state with that specific hook call. Allowing the component to read the latest value of the state in subsequent renders.
The difficult part of this process is:
- How does
useStateknow which component instance it's being called from? - If there are multiple
useState's in a component, how does it remember between renders what state it's associated with?
To solve the first problem, it's not entirely difficult. We just need to track globally which component we are calling when we traverse the component's internal metadata to generate the view tree. Before we call it, we update some globally available object to hold that components metadata. Then inside the useState definition it can read that global variable and know what component it's being called from.
Now for problem #2. We already know how react implements this without looking at the code. One big rule of react is that hooks cannot be called conditionally. But why is that? It's because react uses the order the hooks are called to determine equality of hook calls between renders.
If react makes the assertion that no hooks can ever be called conditionally, and say there's a component that made the following hook calls:
and then the next render it made the following hook calls:
We can trivially say the i'th hook call's in each render are associated with each other, where i=the index of the hook in the order it was invoked.
We can track the current order of a hook call by incrementing a globally accessible counter every time it is called inside the hook's definition and also reading the counter's value when it's called.
In psuedo code it would look like
One way we can use this information is by maintaining an array of "hook state" in our components view node. Where the item in the i'th position belongs to the hook called the i'th time in that component.
Because the currently rendering component is accessible globally, we can access its hook array from the useState function definition, and then index into it using our global counter. If the hook is running for the first time, we simply push initial state to this array.
Then the tuple returned by useState is:
- the value stored at the i'th position in the hook state array
- a closure that has the ability to mutate that hook array with a provided value, and trigger a re-render of the component that defined the state (by capturing the currently rendering component in the closure)
This would look something like
The end code for this hook is almost identical to this example, just with some error checking, proper typing, and referencing real global values. If you want to check it out here is the definition
Now that we defined our first hook, we have a nice way to define what a hook is. It's just a function, but it's a function that depends on information bound to a component.
Re-rendering a component
Now lets move onto our next goal: actually implementing triggerReRender()
It will end up having 3 steps:
- regenerate the view tree, starting from the captured currentlyRenderingComponent in the set state closure
- once the sub view tree is generated, patch the existing view tree (that we store in a global object) to use the newly generated sub tree, transferring over its state to the new view tree
- Given the new, patched, view tree, update the dom
Step 1 will not be that challenging. The generateViewTree function that I showed above is a pure function, and does not operate differently if it's passed the root of the tree, or a sub-tree that is part of a larger tree. So we can just pass it the captured variable in the useState returned closure- currentlyRenderingComponent- and get our new view tree, automatically re-rendering all the children. Because we mutated the hook state array before re-rendering the children, they will read the newest value passed to the set state function.
Now we can move onto step 2, patching the existing view tree. This is also quite simple. We just need to do a traversal of the existing view tree to find the currently rendering components parent, and then just replace the previous node with the newly generated node. To transfer over the state, we can just copy over the components state to the new tree node (this is not the right way to do it, will go over the right way later).
Then using this patched view tree, we will update the dom in a hilariously inefficient manner, and then come back and make a more efficient implementation later. We will take down the entire DOM starting from the root of our react app, and then re-build it using our new view tree. We already have a function that can apply the entire view tree to the dom given a root dom element, so we can re-use that.
Those 3 steps in the function together would look like
And this is all we need for an insanely in-effecient re-render strategy .
Now that we can re-render components, I want to revisit one of our original goals:
- components in the component tree should re-render the same amount of times between implementations
If our view tree is constructed correctly, this should be true. When a parent node changes in react, it unconditionally re-renders its children by default.
But, for the following code, what do we expect the parent-child relationship to be in terms of rendering (using JSX here for brevity):
Another way to ask that question is, if ComponentA re-renders, should ComponentB re-render? Lets take a look at what our current view tree would look like:
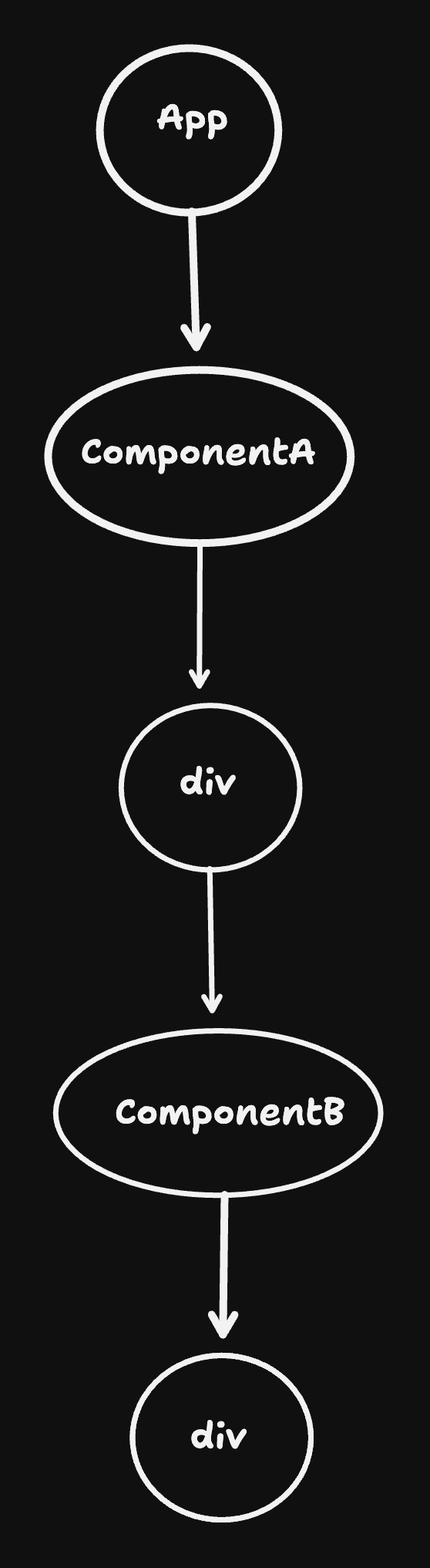
This implies that ComponentA re-rendering should re-render ComponentB. But does it need to? ComponentB will never accept any props from ComponentA, as it was created in App.
If we say that the possibility of a component accepting props from another component creates a dependency between the 2 components, a dependency tree for the above react app would look like:
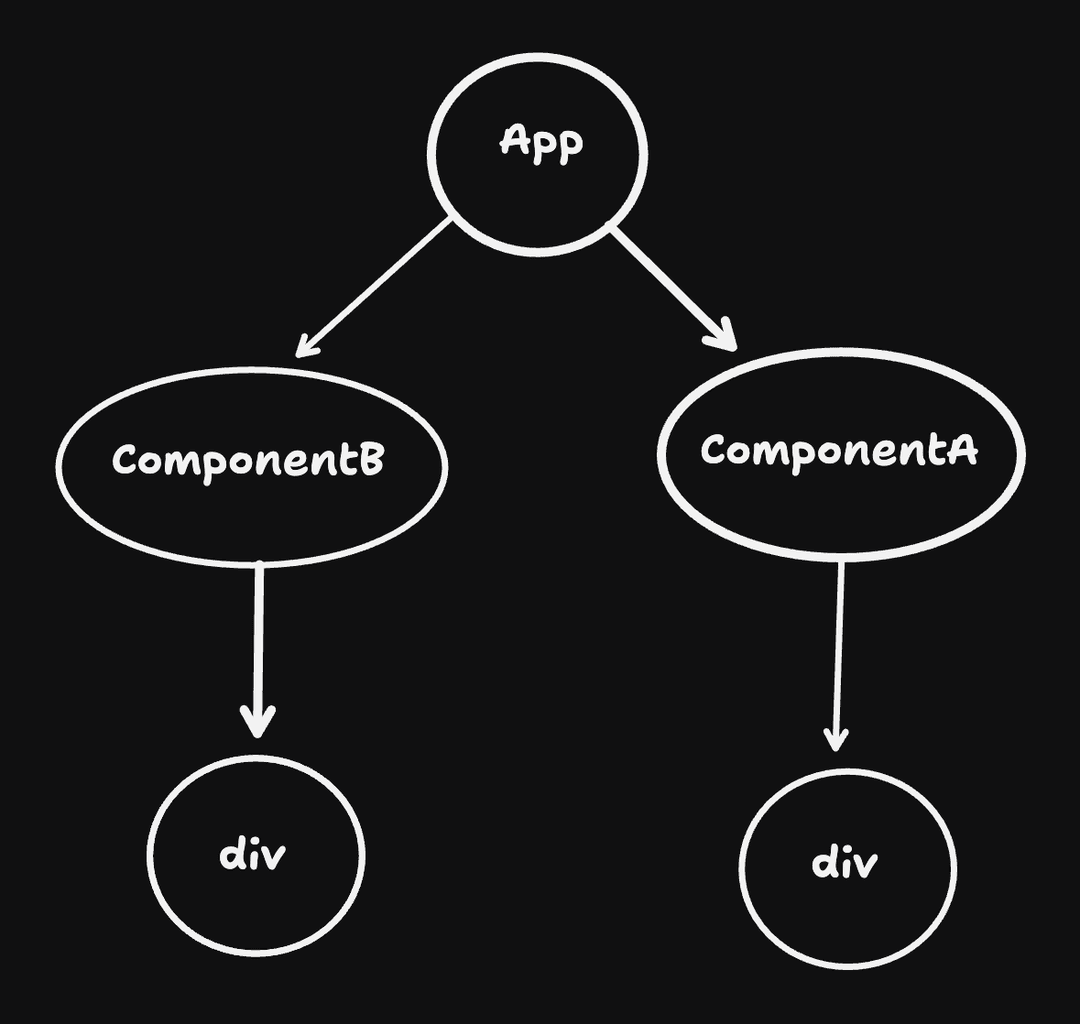
Note, in my actual code on GitHub I refer to the dependency tree as the "RenderTree"
This dependency tree is more inline with how react determines to re-render components. This means we have a bug, as our implementation would re-rerender ComponentB when a sibling (in the dependency tree) changed, because it was a child in the view tree.
We now have 2 tree representations we need to reference to correctly re-render a component. One that determines how the DOM should look, and the other that determines when components need to re-render.
The only information we need to build this dependency tree is knowing which component a given component was called in. The component some given component was called in will be marked as the parent. This works because after you call createElement, there's no way to update the elements props:
So all we have to do is track which component the createElement call happened in to build up a valid dependency tree. We can do this with not too much effort:
- Before a component is rendered, create a dependency tree node for it, and store it globally so
createElementcan access it (essentially the same as the currently rendering component talked about earlier) - For every
createElementcall, push a new render node, representing the component an element was created for, as a child of the globally accessible render node
Note: This strategy is only close to what I ended up doing. I ended up implementing a more roundabout method so it would play nicely with my existing code. The general idea of what I really did was:
- take the output internal metadata by a component (a tree like structure), and flatten it into an array
- If any node inside the array is already in the dependency tree, it must have been called earlier, so filter it out This works because the first return value the element is in must be the component it was created in.
Using this strategy, we can build the dependency tree we were looking for. However, since we're not using it for anything, our components still re-render incorrectly.
We will need to use this dependency tree as we traverse the lazy tree returned by a component:
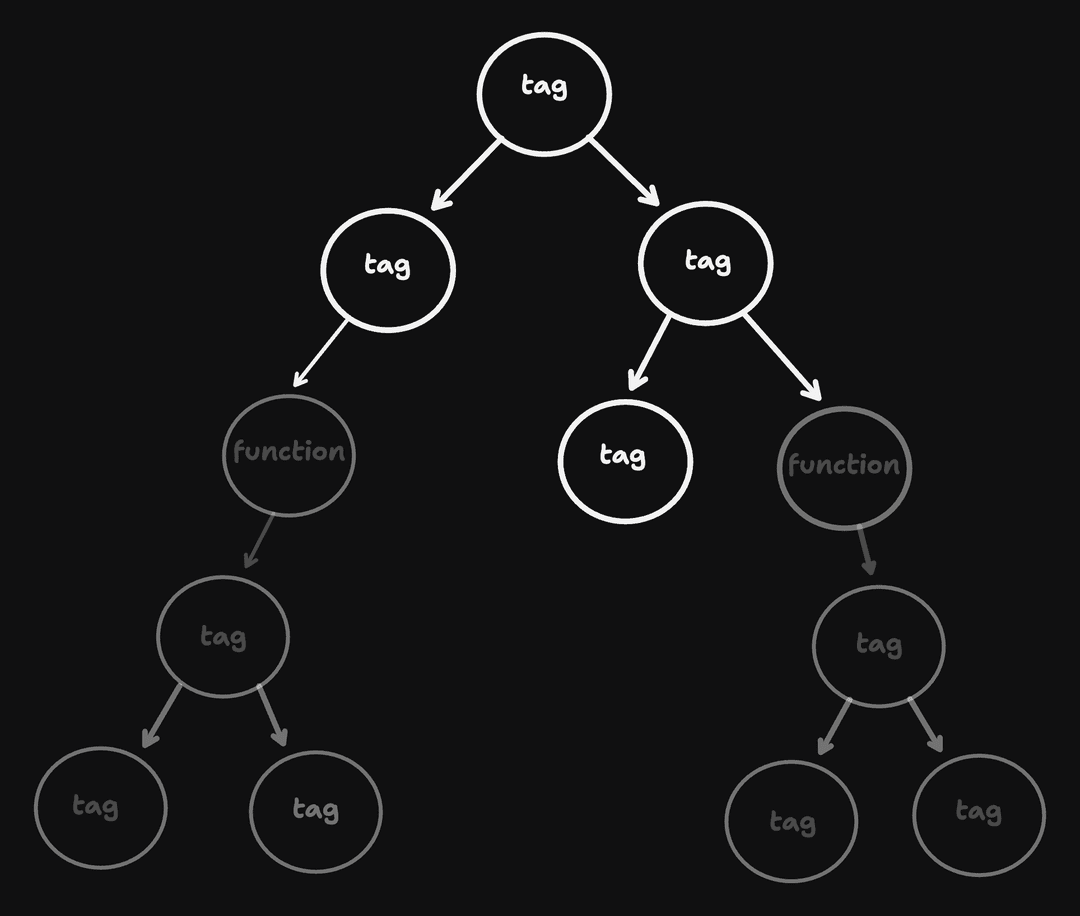
A simple way we can use the dependency tree is as we are generating the view tree, only re-render a component if it depends on the component that triggered the re-render (or if it's never been rendered before)
If both a component is not dependent on the node that triggered the render, and it's not the first render, we can skip rendering that component, and use the previous view tree output by that component- essentially caching the output.
If you want to see in code what this looked like, here's the real implementation that uses this strategy
Reconciling view nodes between render
Our render model is still broken. As mentioned earlier, the way we transfer state between renders is very wrong!
Previously, to make sure state is not lost between re-renders, we just copied the state over for only the component that triggered the re-render
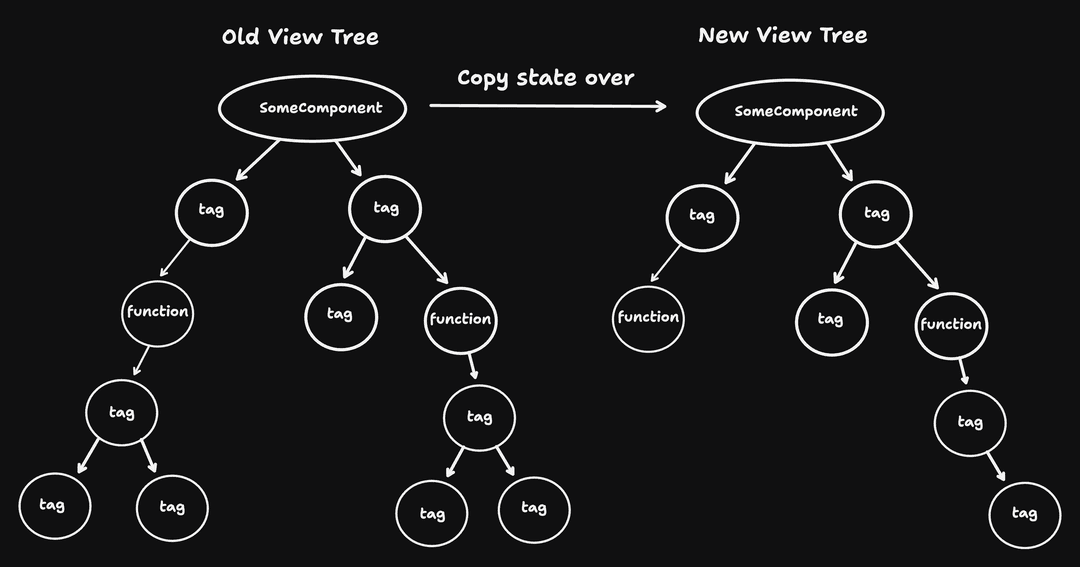
But what about every other component? They will all have re-initialized states, remembering nothing from the previous re-render.
This is a pretty hard problem. We only have the runtime representation of what the tree's "look like". We don't have a compiler that runs over the user's code that tells us which components are equal
What we have to do is determine equality between the 2 trees for every node in the tree, not just the trivial root node.
Lets see how we can do this as a human. For the following example, how would you determine equality between nodes, if you had to make a decision:
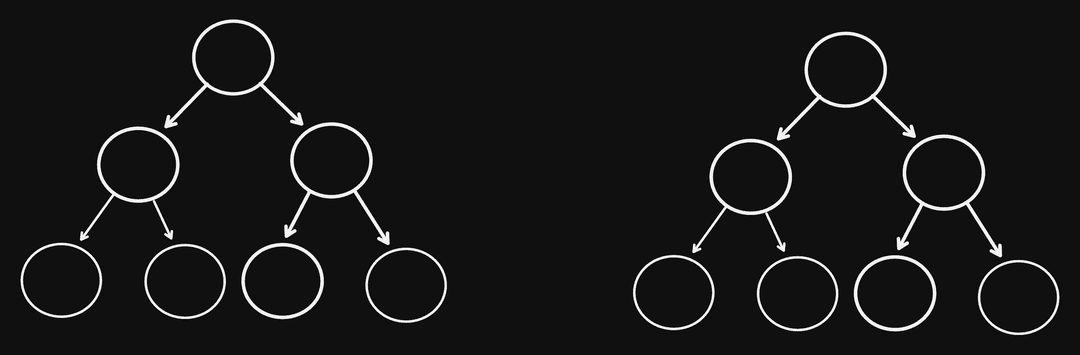
I think the answer is pretty easy here: just match the nodes in the same position:
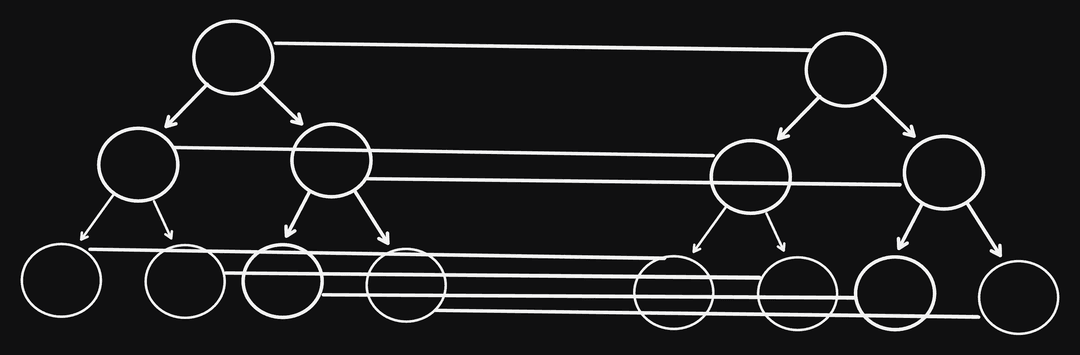
And how do we programmatically define position? We can just say the path to get to the node
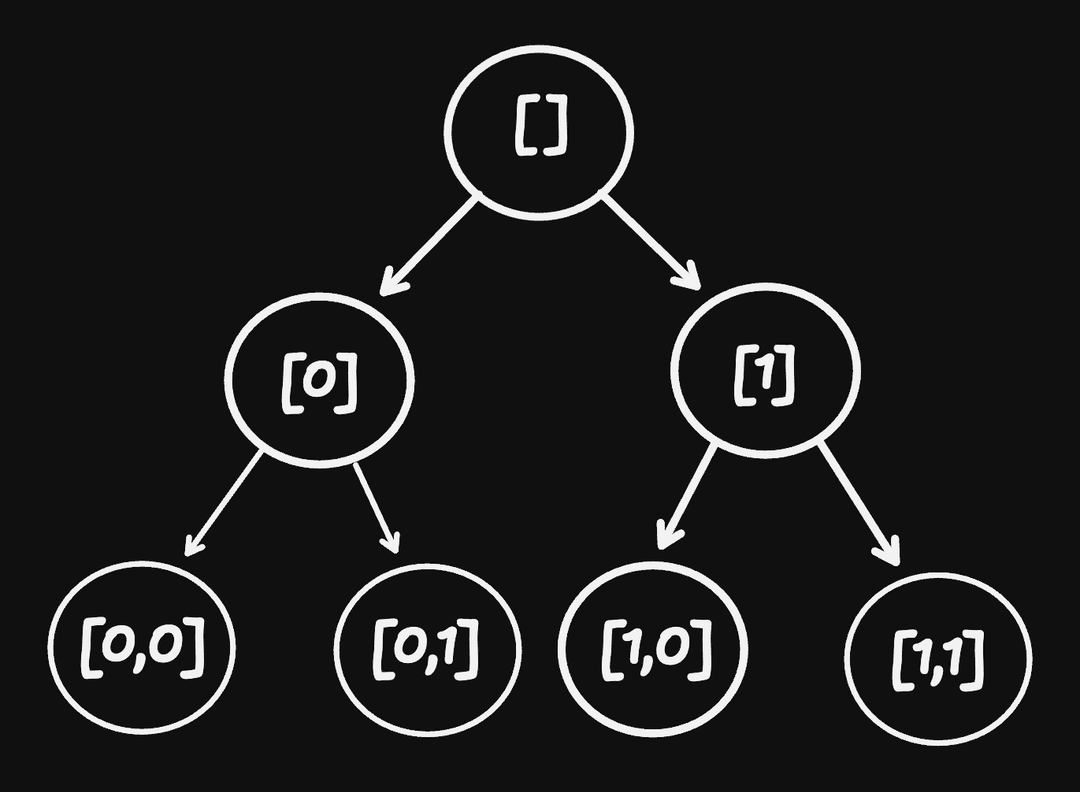
When a node has the same index path between view trees, we can transfer over the state from the previous tree. If there's a new path we can't map (implying its a new node), we don't transfer any state over and let it initialize itself.
This is why react is so crazy about providing keys when rendering lists. If nodes re-order, it will incorrectly determine equality between nodes, and state will be assigned incorrectly to components.
If you want to see what this reconciliation process between tree's looks like in code, here's the link (note, in the final code we take into account the index path AND component name):
Conditional elements
Conditional elements are a core part of react's functionality. Because you're just writing a javascript function that returns react elements, you can of course conditionally return elements:
Or you can conditionally render an element
Where when condition is false | null | undefined react will render nothing to the dom in its place.
Our implementation already handles the first case automatically- since the names are different, we would correctly determine to initialize ComponentB (if the components were both ComponentA, our implementation would consider them the same, but so would React if you don't provide keys.)
Regarding the second case, currently, our createElement function does not take null | false | undefined values as children. And this is what the conditional render compiles down to:
So we need to update createElement to allow null | false | undefined, and to handle it somehow.
The simplest solution would be to filter out all false | null | undefined values. Then anytime one is returned no node will be created for the value, and it's seemingly deleted as we expected?
But we cannot do that. Imagine the following trees generated between 2 renders, where the node at path [0] is conditionally rendered:
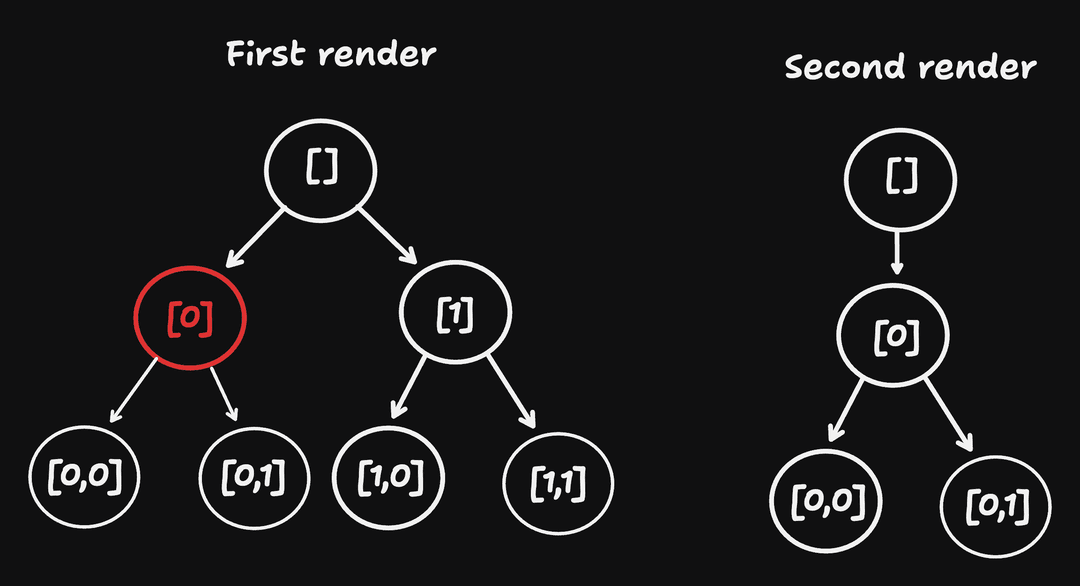
If, in the second render, [0] was replaced with false | undefined | null, we could omit to create a node for it. But then the node at [1] would slip back to position [0], making it look like it was the [0]'th node, and the same goes for its children.
But that would obviously be wrong, and would mean we would have to require keys for components anytime the user wanted to conditionally render them. Which react does not ask users to do.
Instead, we could represent false | undefined | null as an empty slot in our tree. Where false | null | undefined create valid react elements to place on the tree. They just have no metadata and no children. This way, our tree will be stable between renders:
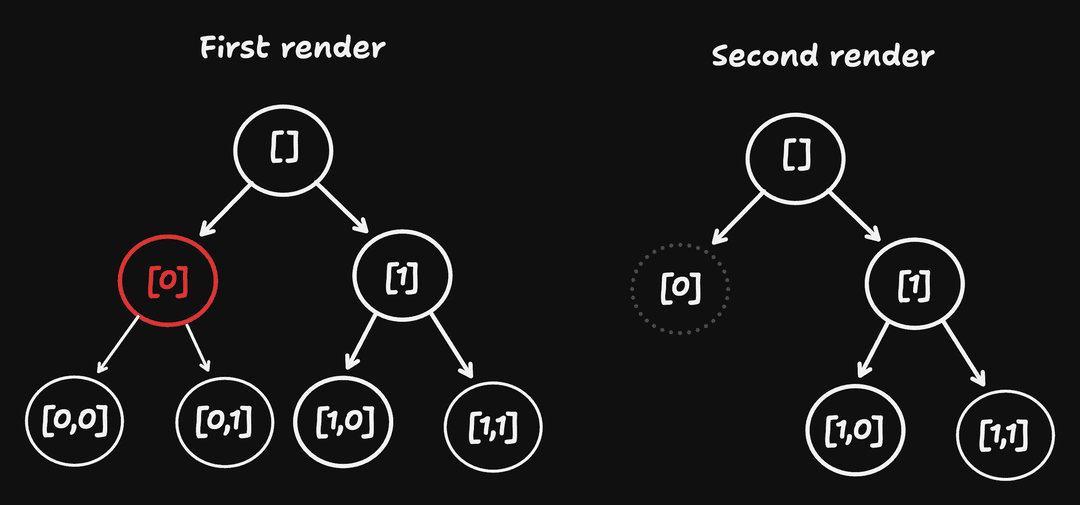
Anytime we attempt to render an empty slot, we just skip it. It has no children and cannot output anything. All our nodes still exist in the same position, so we can correctly transfer state between renders.
Efficient dom updates
Currently we take down the entire dom every time anything re-renders. Obviously react does not do this. It will only update the needed dom nodes.
We already went over how we can determine equality between trees- the path to the node. This strategy will be very useful for updating the dom.
We will be comparing the new and old view trees after re-rendering a component. As we find tag nodes that have matching index path's, we pass the props of the new view node directly to the HTML tag. React has a light abstraction of this with their synthetic event system. But essentially does the same thing.
If a new node has no node it can match to from the previous tree, it must be a new node, and we create a new HTML element for it.
If an old node has no node it can match to from the previous tree, it must no longer exist, so we delete the existing HTML element for it.
This is really all that's needed to have pretty efficient dom updates. The actual code i wrote for this seems quite a bit more convoluted than what I described since there's some book keeping needed because of conditional elements (empty slots).
If a view tree node becomes an empty slot between renders, we have to delete the associated dom node. And if the empty slot turns into a real element, we have to insert it into the dom at the right position.
More hooks
Now that our core render model is for the most part done, we can implement some fun hooks
useRef
This is an extremely easy hook to implement. It simply binds an immutable reference to your component, allowing you to change the contents at the reference arbitrarily, not causing a re-render.
To adapt the example code for useState, it would look something like
The core part missing is there is no trigger re-render. Otherwise, it's still data bound to the component and acts very similar to the state returned by useState.
useEffect
Now let's move to useEffect. useEffect has 3 core components:
- The effect callback
- The effect dependencies
- The effect cleanup
Every time the dependencies change or the component is first mounted, the effect callback is called. If the effect callback returns a function, it will be called before the next effect, acting as a cleanup function for any setup logic performed in the effect callback.
The useEffect hook is also quite simple to implement, especially because of how complex it can feel in some codebases.
We follow a similar process to useRef and useState: We read the currently rendering component, index into its hooks, and initialize it if the component hasn't already been rendered.
But we have one extra step. If the dependencies changed compared to the previous render, measured with shallow equality (===), then we update the effect callback of the hook state and its dependencies. If the dependencies change, then the previous callback has a closure over stale values, so we need the newly computed closure (remember, a closure is just a special object, and we want the latest one).
We are done setting up the effects for the components, but this function definition does not handle calling the effect or effect cleanup. This happens after the render completes.
Unsurprisingly, the actual location in the code where we will call the effects is after we call the component's render function.
We will have to map over all the effects the component holds, check if the dependencies changed compared to the previous render, and if they did:
- call the effect cleanup if there is one
- call the effect
- if the effect returns a callback, set it as the new cleanup function in the hooks state
And this is the exact code needed to implement this:
not bad at all
useMemo
There tends to be a lot of misinformation about useMemo and how you should avoid them because of the overhead they generate. But let's see if that's really the case.
useMemo accepts a function that outputs a value and returns that value by calling the function. The special part about useMemo is that it also accepts an array of dependencies. If those dependencies don't change between renders, it will not call the function again; instead, it will re-use the last output of the function. If they do change, the function will run again, and that value will be returned going forward.
This is a way to optimize your components because you can avoid unnecessarily re-computing values. But, this is only true if the overhead of the memoizing check is less than the overhead of calling the function. But we can define well what that overhead is since we're implementing the hook:
It will be very similar to the useEffect implementation. We need to do all the initial setup logic to get the hook state, or initialize it if it's the first render. Then we check if the dependencies changed, just like useEffect. The difference is if the dependencies change in useMemo, we call the provided function. Else, we return the previous value:
In our implementation, the overhead to call useMemo is quite low! All we do is some cheap if statements on a more-than-likely small array. Even in javascript, this is quite fast.
I took the liberty of checking out react's implementation after the fact. And it is quite basically identical (check it out here, along with basically every other hook)
Here's the code if you don't want to click links:
Where areHookInputs equal simply does:
This means if your function does more computation than the computation required to perform deps.length shallow equals, you're probably better off using useMemo.
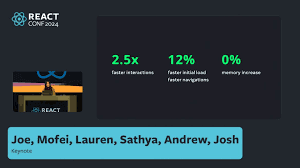
This was also proven at scale with the react compiler- a compiler that memoizes basically everything. They applied it to the Instagram codebase and saw no increases in memory and huge improvements to to interactivity:
useCallback
Now that we have implemented useMemo, let's implement useCallback.
Drumroll, please.
useCallback is, literally, useMemo that returns a function. It is slightly less awkward to read than
And because I was curious, I later checked out reacts implementation:
And it was, for the most part, the same implementation as useMemo:
useContext
useContext is special compared to most other hooks. This comes from useContext not being responsible for creating any state when called. It's
only responsible for reading state, which is being shared higher up the tree.
The functionality required to share this state is not part of the hook. It originates through a context provider- a special component.
Here's an example usage to make sure we're on the same page
createContext acts as a factory to create a special Provider component that holds data. Components read this data by calling useContext and passing the return value of createContext. Telling useContext to search up the view tree until it finds the provider created by the same context.
Notice how I said we search up the view tree, not the dependency tree. A component may be a sibling of another component in terms of the dependency hierarchy, but a child in terms of the view hierarchy and would still be able to read the context. For example:
If SomeContext.Provider is a component, it is a sibling of SomeComponent in the dependency tree. But, we expect SomeComponent to have the context state available to it when calling useContext(SomeContext). So we can say that the tree useContext searches up must be based on the view tree.
You might think this means that SomeComponent now depends on SomeContext.Provider, and we should update the dependency tree to represent that, but that's not the case.
While SomeComponet does read data provided by SomeContext.Provider, SomeContext.Provider simply broadcasts a value, it's not creating react state that can be updated + cause a re-render (there is no setter associated with it).
For the data inside the provider to change, there must be a state change triggered by an ancestor of SomeContext.Provider (all the data the provider holds must come from a component it depends on, since it was passed as props). And because SomeComponent + SomeContext.Provider are siblings (in the dependency tree), they share the same ancestors and will be re-rendered together. Allowing SomeComponent to read the newest value broadcasted by SomeComponent.
If instead SomeContext.Provider broadcasted a value that is not react state; it would simply be static, and there would be no reason to have a dependency on something that will never change.
With that out of the way, let's start with implementing createContext, the function that creates the special provider component.
Currently createElement only returns metadata about the component it instantiates. This metadata includes props, the function or html tag, and its children.
For a provider component, we can assign the data we want to distribute to the decedents of the component by adding a property on the internal metadata that stores it. Then, we set it
only when we create the metadata using createContext.
Later, when we call useContext(SomeContext), we read up the view tree and look for a node that has a provider equal to SomeContext.Provider, and if it does the data will be available to read.
Here's what the implementation of createContext looks like:
- Note that the element type i passed was a div. This is obviously wrong. What we really want to do here is something like a fragment. For now I wont implement it because I don't think it's a core feature of react.
- Note, previously, our view tree nodes only carry information about their child nodes. So, we would have to do a potentially expensive traversal to move up the tree and check if an ancestor node has the provider we are looking for. To avoid this, I ended up performing a minor optimization and de-normalizing the view tree by storing the parent as a property on the child node.
If we don't find the provider up the tree, we want to return the default value passed to createContext. This was the unexplained part about the above createContext implementation. What we can do is store the default values in a global array. When a provider is not found, the useContext function can fall back to reading the default values. This behavior is very similar to how programming languages behave when a value is not found in any ancestor scope- fallback to looking into the global scope.
Lets now look at what the useContext implementation would look like since all the pieces needed are finished:
Something you may have noticed in our useContext implementation is we never incremented the hooks called by one or mutated the render nodes hook array. This is because we read the context data based on an ID that is created outside of the react tree (createContext), and because useContext creates no data that needs to be persisted across renders, it only reads. So we are not limited by the order it was called.
This means we can call it conditionally with no problem. This holds true even in normal React- the following is perfectly valid:
And this is the same behavior react's new use hook has, which can be used to read context.
Final result
Lets finally see an example of all of it put together!
The below example shows off a sample app with context, state, memoization, fetching in useEffects, conditional rendering, list rendering, deep props, and efficient dom updates!
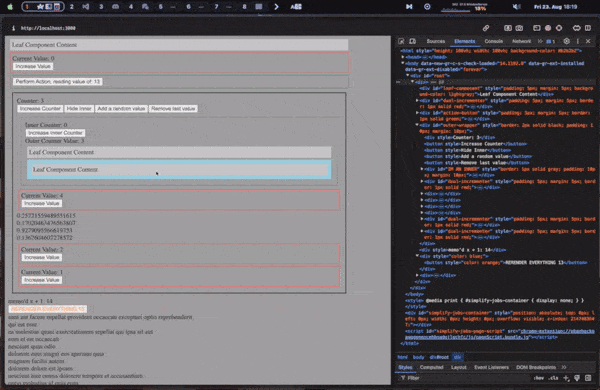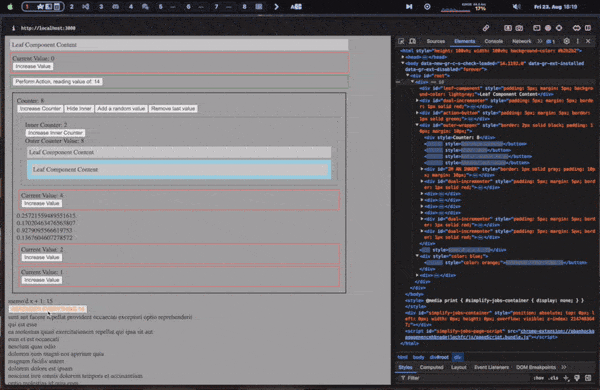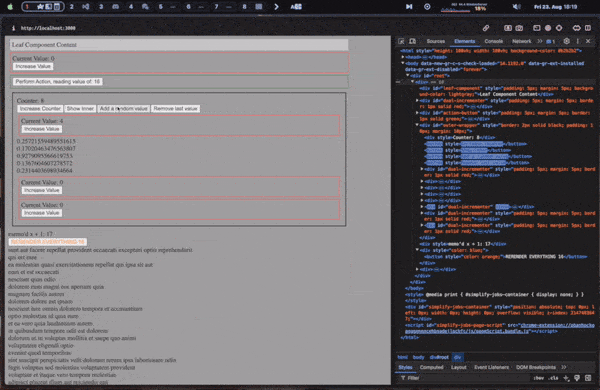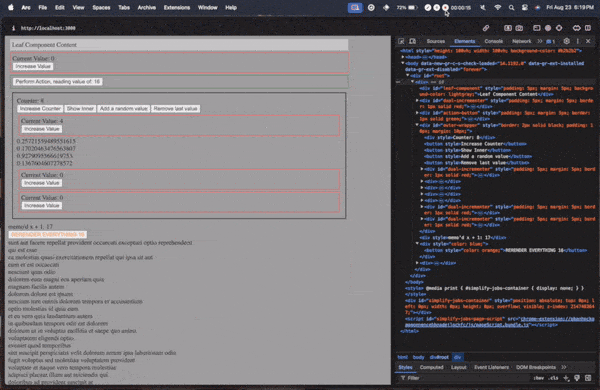
Conclusion
Re-building libraries from scratch is a pretty great way to get intuition as to why the library made certain decisions. You also end up building a strong internal model of the library, and that allows you to reason through scenarios you may of never encountered. It's also a great way to learn about hidden behaviors you definitely would not of thought about without building the library.
If you end up doing a deep dive on the entire codebase, you will likely notice things are more complicated than they seem in my explanations here. There is a lot of complexity added by my skill issues/ mistakes made early on that would take too long to rectify. If I rewrote this, I think I could probably do it in 1/3 the lines.
Anyways, I did my best to distill the core ideas of the codebase into something explainable here. If you have any questions about how something is implemented, or you encounter a bug (I'm sure there's many) feel free to make a GitHub issue, and I'll be sure to respond!
In the future, I do want to take this further in a few ways:
-
implementing server-side rendering
- this would involve building a string, instead of a dom, from the view tree
- We would have to find a way to map the HTML generated by the server to the view/dependency trees generated by the client side react. This would formally be known as hydration.
-
different render targets
- there's no reason we have to generate a dom from our view tree. Any UI that has any hierarchial structure can pretty easily use the implemented react internals here
-
reimplement this in swift
- i've had to use UIKit recently for a job, and very much miss react. Something inside me very much wants to port this to swift.
- Instead of dom elements the library would create UIViews
Hopefully, you got something out of reading this. If you're interested in more stuff about react internals, and this article made somewhat sense to you, I recommend going ahead and just reading the react source code. No better place to learn more about react than react itself